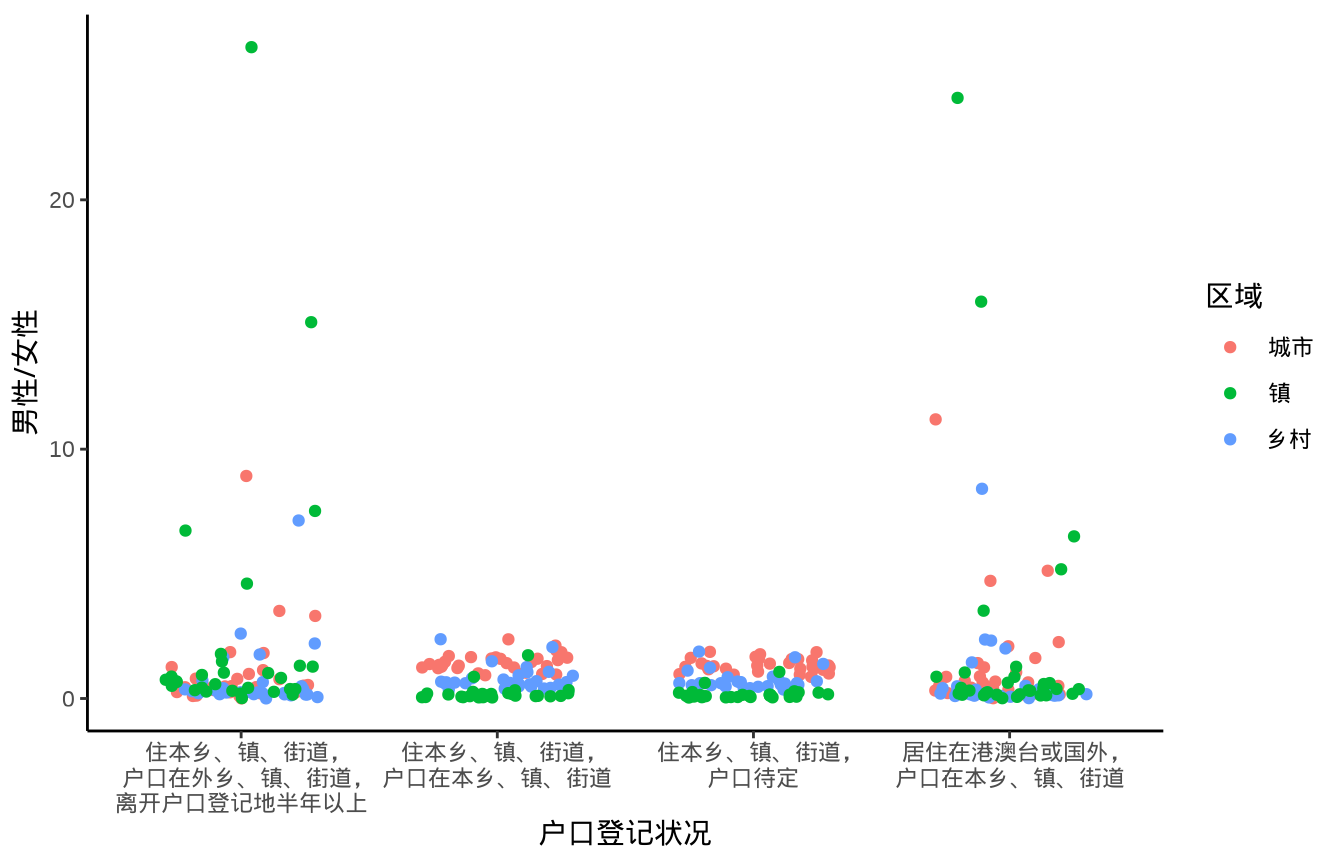
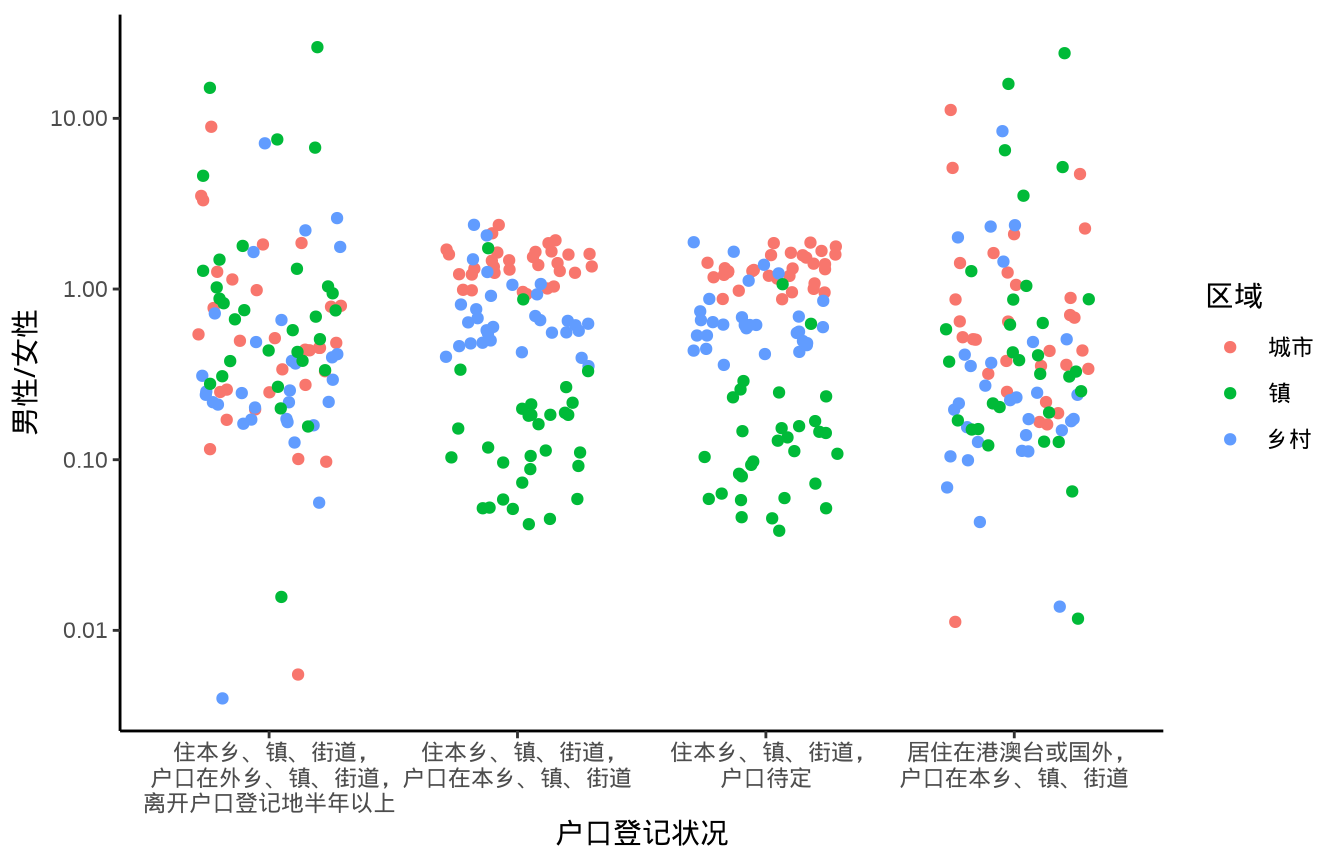
在 R 语言中,函数 pbinom() 可以计算上述二项分布的上分位点对应的概率为 \(0.0127952\)。
pbinom(q =3, size =10, prob =0.1, lower.tail = F)
#> [1] 0.0127952
首先简单回顾一下置信区间,在学校和教科书里,有两种说法如下:
\(1-\alpha\) 的把握确定区间包含真值。
区间包含真值的概率是 \(1-\alpha\)。
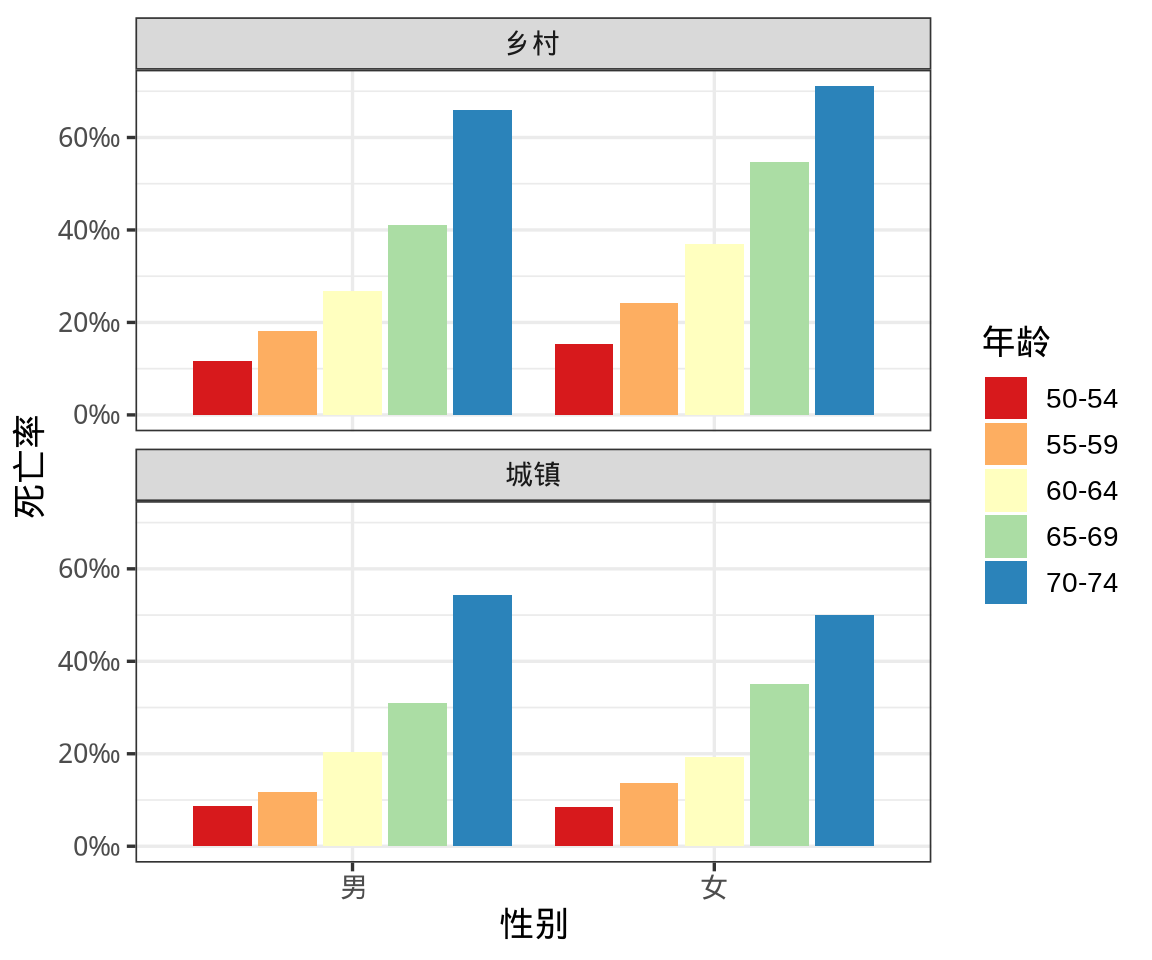
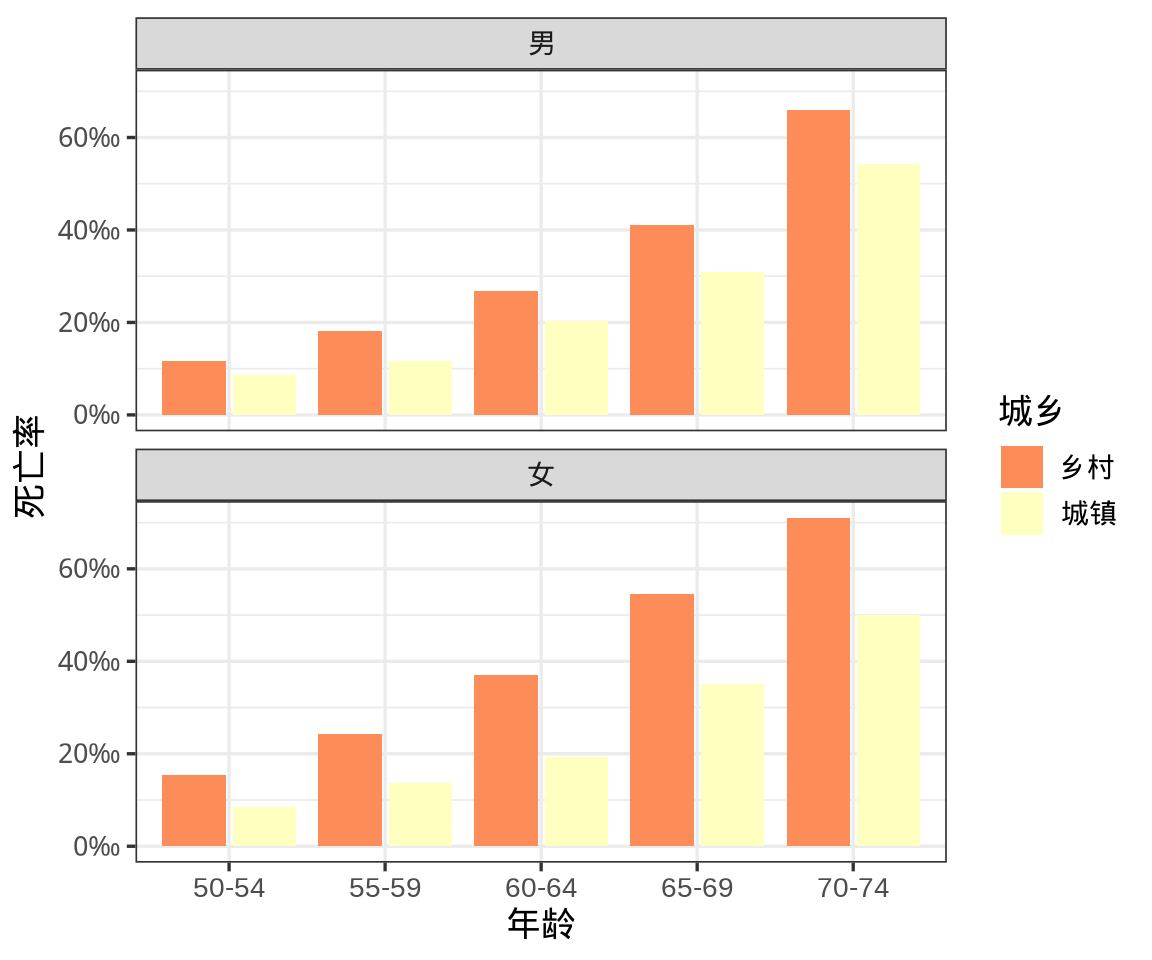
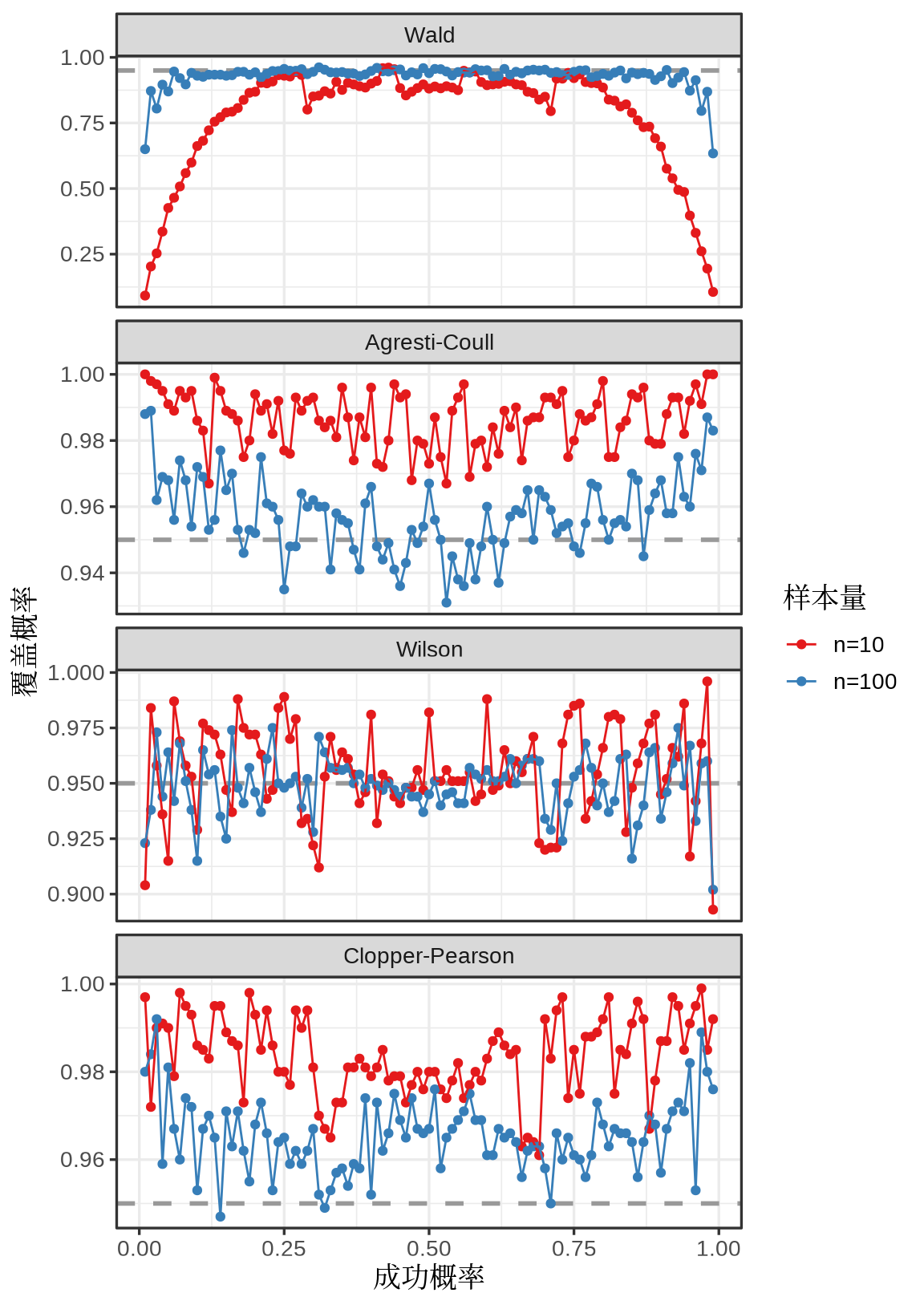
为什么要采纳第一种说法而不是第二种呢?这其实涉及到置信区间的定义问题,历史上 E. S. Pearson 和 R. A. Fisher 曾有过争论。和大多数以正态分布为例介绍参数的置信估计不同,下面以二项分布为例展开介绍。我们知道二项分布是 N 个伯努利分布的卷积,而伯努利分布又称为 0-1 分布,最形象的例子要数抛硬币了,反复投掷硬币,将正面朝上记为 1,反面朝上记为 0,记录正反面出现的次数,正面朝上的总次数又叫成功次数。
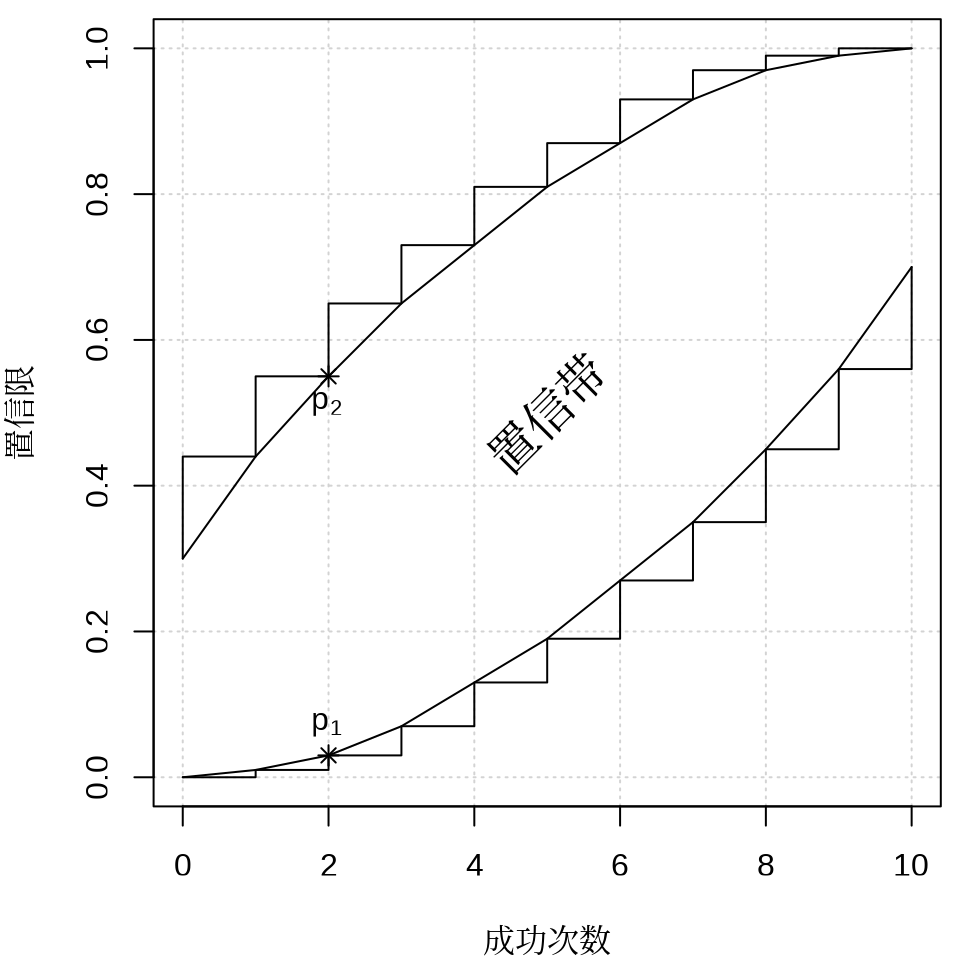
1934 年 C. J. Clopper 和 E. S. Pearson 在给定置信水平 \(1- \alpha = 0.95\) 和样本量 \(n = 10\) 的情况下,给出二项分布 \(B(n, p)\) 参数 \(p\) 的区间估计(即所谓的 Clopper-Pearson 精确区间估计)和置信带 (Clopper 和 Pearson 1934),如 图 12.8 所示,横坐标为观测到的成功次数,纵坐标为参数 \(p\) 的置信限。具体来说,固定样本量为 10,假定观测到的成功次数为 2,在置信水平为 0.95 的情况下,Base R 内置的二项精确检验函数 binom.test(),可以获得参数 \(p\) 的精确区间估计为 \((p_1, p_2) = (0.025, 0.556)\),即:
# 精确二项检验 p = 0.2binom.test(x =2, n =10, p =0.2)
#>
#> Exact binomial test
#>
#> data: 2 and 10
#> number of successes = 2, number of trials = 10, p-value = 1
#> alternative hypothesis: true probability of success is not equal to 0.2
#> 95 percent confidence interval:
#> 0.02521073 0.55609546
#> sample estimates:
#> probability of success
#> 0.2
值得注意,这个估计的区间与函数 binom.test() 中参数 p 的取值无关,也就是说,当 \(p = 0.4\),区间估计结果是一样的,如下:
# 精确二项检验 p = 0.4binom.test(x =2, n =10, p =0.4)
#>
#> Exact binomial test
#>
#> data: 2 and 10
#> number of successes = 2, number of trials = 10, p-value = 0.3335
#> alternative hypothesis: true probability of success is not equal to 0.4
#> 95 percent confidence interval:
#> 0.02521073 0.55609546
#> sample estimates:
#> probability of success
#> 0.2
由此,也可以看出区间估计与假设检验的一些关系。
library(rootSolve) # uniroot.alloptions(digits =4)# r 为上分位点p_fun <-function(p, r =9) qbinom(0.025, size =10, prob = p, lower.tail = F) - r # 上分位点l_fun <-function(p, r =9) qbinom(0.025, size =10, prob = p, lower.tail = T) - r # 下分位点# 计算每个分位点对应的最小的概率 pp <-sapply(0:10, function(x) min(uniroot.all(p_fun, lower =0, upper =1, r = x)))# 计算每个分位点对应的最大的概率 ll <-sapply(0:10, function(x) max(uniroot.all(l_fun, lower =0, upper =1, r = x)))plot(x =seq(from =0, to =10, length.out =11),y =seq(from =0, to =1, length.out =11),type ="n", ann =FALSE, panel.first =grid(),family ="sans")title(xlab ="成功次数", ylab ="置信限", family ="Noto Serif CJK SC")lines(x =0:10, y = p, type ="s") # 朝下的阶梯线lines(x =0:10, y = p, type ="l") # 折线# points(x = 0:10, y = p, pch = 16, cex = .8) # 散点# abline(a = 0, b = 0.1, col = "gray", lwd = 2, lty = 2) # 添加对称线text(x =5, y =0.5, label ="置信带", cex =1.5, srt =45, family ="Noto Serif CJK SC")# points(x = 5, y = 0.5, col = "black", pch = 16) # 中心对称点# points(x = 5, y = 0.5, col = "black", pch = 3) # 中心对称点lines(x =0:10, y = l, type ="S") # 朝上的阶梯线lines(x =0:10, y = l, type ="l") # 折线# points(x = 0:10, y = l, pch = 16, cex = .8) # 散点points(x =c(2, 2), y =c(0.03, 0.55), pch =8, col ="black")text(x =2, y =0.55, labels =expression(p[2]), pos =1)text(x =2, y =0.03, labels =expression(p[1]), pos =3)
Blyth, Colin R., 和 David W. Hutchinson. 1960. 《Table of Neyman-Shortest Unbiased Confidence Intervals for the Binomial Parameter》. Biometrika 47 (3/4): 381–91. https://www.jstor.org/stable/2333308.
Brown, Lawrence D., T. Tony Cai, 和 Anirban DasGupta. 2001. 《Interval Estimation for a Binomial Proportion》. Statistical Science, 期 2: 101–33. https://projecteuclid.org/euclid.ss/1009213286.
Clopper, C. J., 和 E. S. Pearson. 1934. 《The Use of Confidence or Fiducial Limits Illustrated In The Case of The Binomial》. Biometrika 26 (4): 404–13. https://doi.org/10.1093/biomet/26.4.404.
Geyer, Charles J., 和 Glen D. Meeden. 2005. 《Fuzzy and Randomized Confidence Intervals and P-Values》. Statistical Science 20 (4): 358–66. https://www.jstor.org/stable/20061193.
Marron, J. S., 和 Ian L. Dryden. 2022. Object Oriented Data Analysis. 1st 本. Boca Raton, Florida: Chapman; Hall/CRC.
Pu, Xiaoying, 和 Matthew Kay. 2020. 《A Probabilistic Grammar of Graphics》. 收入 Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems, 1–13. ACM. https://doi.org/10.1145/3313831.3376466.
Wilson, Edwin B. 1927. 《Probable inference, the law of succession, and statistical inference》. Journal of the American Statistical Association 22 (158): 209–12. https://doi.org/10.1080/01621459.1927.10502953.